NLP ITALIA
Il primo blog di NLP completamente in italiano
Pubblicato inSenza categoria
Come allenare un modello Word2Vec per l’italiano
In questo tutorial vedremo come trainare un modello Word2Vec per la lingua italiana sul corpus di Wikipedia. Esistono moltissimi modelli pretrainati per l’italiano (ad esempio ce ne sono diversi inclusi in Spacy), ma penso che, almeno una volta, possa essere…
Pubblicato inNLP classica
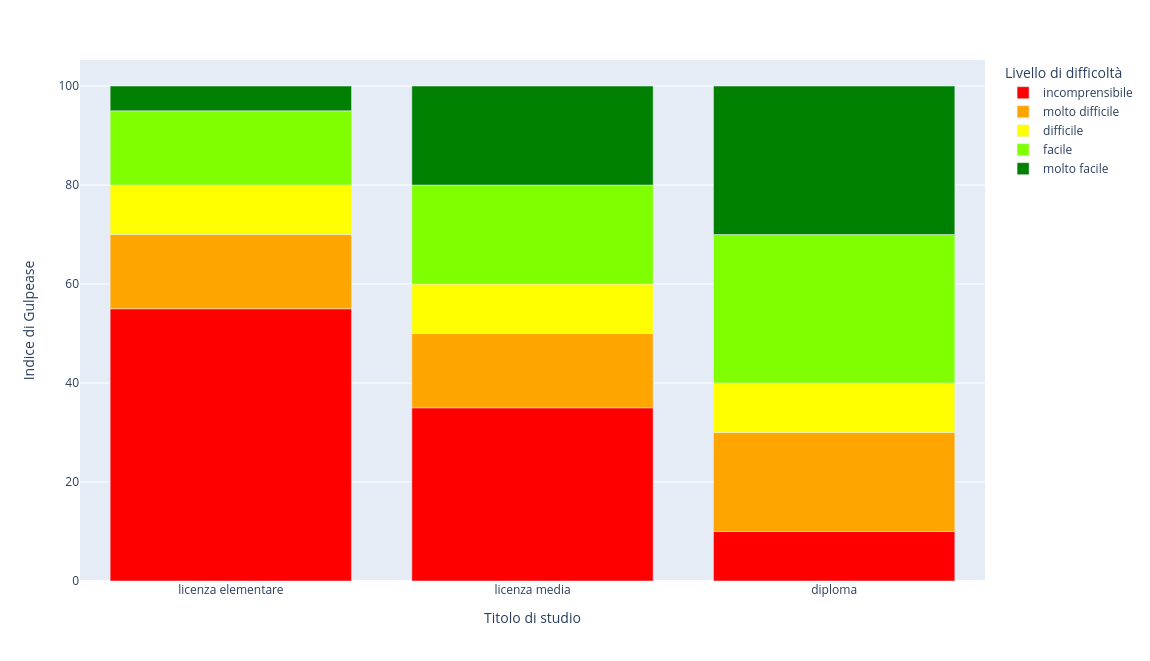
Leggibilità di un testo: l’indice di Gulpease
Nel post di oggi parleremo dell’indice di Gulpease, un indice di leggibilità dei testi per…

Pubblicato insentiment analysis
Analisi del sentiment con la regressione logistica
In questo articolo vedremo come creare un primo, semplice, modello di NLP per l’analisi del…

Pubblicato inpreprocessing dei testi
TF – IDF: quali parole sono importanti?
Spesso gli algoritmi di NLP lavorano su corpora che contengono decine (se non centinaia) di…
Pubblicato inpreprocessing dei testi
Stemming e Lemmatizzazione
Nel post precedente, abbiamo visto come segmentare un testo in token. Nel caso di gran…
Pubblicato inpreprocessing dei testi
Tokenizzazione
Con il termine tokenizzazione si intende la riduzione di un testo in unità semantiche fondamentali chiamate tokens. Nella stragrande maggioranza delle applicazioni i token corrispondono alle parole (word tokenization), ma in casi particolari possono essere anche sillabe, frasi, paragrafi o…